兩年前也上過凱堂大哥上的UML課程,當時因為SLIM要OPEN出去,所以老師希望我對SLIM做一些UML的diagram和文件。
當初還買了兩本書來看
UML 2.0 學習手冊
這本還不錯,滿淺顯易懂的
UML 2.0 技術手冊
這本就講的比較詳細了
對SLIM的UML有興趣的話,可以下載看看
裡面包含了大多的diagram以及EA的檔案
只是內容可能不太完善或者完美,請大家見諒
下載
當時的投影片
sequence diagram
slim analyzing
2009年3月31日 星期二
ICASSP 2009 Tutorials
以下節錄自系辦寄來的通告信。想問大家有人有要參加的嗎?維城學長說IRCAM的葉中興博士應該會來。
IEEE-ICASSP 2009
國科會全額補助國內學生參加密集課程(Tutorials),請多利用。
本補助原則為先申請先補助,申請從速,額滿時隨時截止。申請者必須具備學生身分。申請請上網填申請表:http://speech.ee.ntu.edu.tw/~RA/tutorial
額滿後主辦單位會通知獲補助之學生及其受補助課程,及補辦課程註冊之程序。補辦註冊時受補助學生需先自行繳交註冊費(每門課程60元美金),待大會結束後請將在會場取得註冊費之正本收據郵寄至國立台灣大學電機二館531室,再由大會發放補助款。(這部份好像最麻煩 = =)
IEEE-ICASSP 2009在4月19-20日3個時段共安排17場密集課程(Tutorials)。http://www.icassp09.com/Tutorials.asp
聽完課後要繼續聽presentations也是可以。
2009年3月19日 星期四
騰雲駕霧程式競賽
睽違已久的趨勢程式競賽又再度出現了,對當時還是大學生的我而言,趨勢的比賽是一個大消息,開口粥大師最近較忙,就由小弟我來代貼有關比賽的資訊。注意!3/24(二) 12:20-13:30 在成大資工4263有舉辦說明會。另外請隨時注意官方blog所公佈的 training course 消息。
以下是資訊來源:
騰雲駕霧程式競賽官網: http://www.trend.org/fd/tabid/66/Default.aspx
騰雲駕霧程式競賽官方 blog: http://www.wretch.cc/blog/trendnop09
騰雲駕霧程式競賽偽官方 blog: http://keikoblog.blogspot.com/2009/03/blog-post_10.html

我們公司辦的比賽,有興趣的人,尤其是學長弟妹可以參加唷!節錄一些重點:
「騰雲駕霧程式競賽」由趨勢科技主辦,IBM生物資訊研發中心協辦,該單位將提供硬體設備贊助。競賽籌備小組自3月10日起將至台北科大、台大、清大、交大等9所大專院校進行巡迴說明…
- 說明會時間地點
3/11(二) 12:20-13:30
北科大
綜合科館第三演講廳3/11(三) 13:00-14:00
台大
資工系 1023/12(四) 12:10-13:20
台科大
IB5103/16(一) 12:20-13:30
中山
電資大樓 F10013/17(二) 11:00-12:00
中央
工五館 2073/18(三) 15:00-16:00
清大
資電館 1273/19(四) 12:20-13:30
交大
工三 1223/23(一) 14:00-16:00
中正
地震館 2153/24(二) 12:20-13:30
成大
成大資工 4263 - 報名資格
大學生、研究生、每隊四人(不多不少唷),可跨校! - 報名
3/20-5/15:將開放網路報名,6月份將安排參賽者接受第一階段的網路遠距教學! - 比賽方式
- 初賽
7/1:網路公佈題目。
7/8:00:00 停止收件。
7/22:公佈入圍名單。 - 決賽訓練課程
7/30 ~ 7/31:到趨勢上課! - 決賽
8/18 ~ 8/19:決賽入圍。今年也有可能不會在台北士林劍潭青年活動中心,會改去 IBM 生物資訊研發中心吧?機器都在那邊,或是要很炫的自己遠端 deploy 到伺服器海中,那就不必到現場了!
- 初賽
- 頒獎
8/20:頒獎。往年頒獎典禮都蠻有心的,會找飯店,以前有去過晶華酒店,典禮有簡單的點心、可邀請家人朋友、找記者來採訪(不過記者好像都不會來-_-|) - 獎項(這好像是最重要的)
1st:NT$500,000
2nd:NT$300,000
3rd:NT$200,000
4th:NT$150,000
5th:NT$100,000
6th ~ 10th:NT$50,000
預聘書現在只給前三名了 - 題目
好像沒提到,但是跟雲端運算有關就是! - 競賽網站
http://www.trend.org/fd/tabid/66/Default.aspx - 附註
比賽中會需要各式各樣的人,寫 UI、寫程式、寫文件、上台 presentation、找 bug、做 testing 都會,所以記得要把團隊技能平均問題,不要只點某一、兩樣技能唷!
我是工作人員,不管有什麼疑難雜症、難以啟齒需要匿名的問題,我都可以代為傳達唷!
2009年3月18日 星期三
在 blog 上貼 YouTube
網友 Alvin 最近詢問怎麼在 blog 上嵌入 YouTube 一類的元件,所以就來跟大家介紹一下,順便騙騙文章數,掩飾一下自己江郎才盡了…
步驟一
YouTube 之類的服務都有提供物件語法給大家複製到自己的網頁上,參考下圖可以看到網頁有一區標示著嵌入。

步驟二
滑鼠移過去,還會發現有自訂的功能。使用者可以根據自己的需求調整,調整後,就是把 <object> …開頭的語法複製起來。

步驟三
開啟自己 blog 文章編輯的 html 模式,以 WLW 為例,就是切換到程式碼模式。 接著就勇敢的貼上吧!

成果
最後,就可以看到成果了!
其他
其他像是 mp3, quicktime 等格式的多媒體資料,基本上只要 host 有提供 object 來嵌入,都可以在網頁上產生美美的元件。
結語
ㄜ,感覺教學最後就要來個結語,那就: Yes, We Can!
HHT – Hilbert Huang Transform
Key words : Hilbert-Huang transform, Hilbert spectrum, Hilbert transform
這個演算法,是利用Empirical Mode Decomposition(EMD)將原訊號拆解成數個Intrinsic Mode Functions (IMF)。今天我整理一下以音高為D4的小提琴為輸入所做的實驗結果。
整個 Hilbert Analysis流程如下圖所示(謝志敏, 2007)。



一開始先做 EMD,先找出整段訊號的 local maxima & minima,然後用 cubic spline line分別造出envolope,最後再將這兩個envelope取平均,即為第一個分量;依此類推,直到這個平均後的值趨近於水平線時,該訊號即為第一個 IMF。收斂條件依定義為一名為 SD 的式子,不過實驗的程式是執行 10 次 iterations。
小提琴做完的結果如下圖所示。由上至下依次為原音(當作是IMF 1)、IMF 2, 3, 4, 5, 6。音檔在這裡,可直接下載。

聽過音檔後,大家應該不難發現,IMF 2 的頻率較高,IMF 5 聽起來像是心跳聲,噗通一下就沒了。其實依傳統EMD作法,解出來的 IMF 順序,其瞬時頻率是由高往低的,有點類似像 band pass filter。由圖可知,IMF 4的頻率是最接近原音音高的地方,所以能量最大,而 IMF 5只剩起頭音的部份有聲音。
小結:
IMF 5 只有起頭音跟後面一小段(?)有訊號,可能會是我要做 noise modeling 時所需要的元素。而年前老師要我改變 maxima & minima envelope的擷取方式,希望能先抓出較完整的 sine wave,目前做出來效果並不理想,一來是envelope要抓得很完美不好做,二來是 IMF 依舊有從高頻先被取出來的特性。
投影片:下載。
2009/02/20 Progressive Report
目前的實驗是先將頻率考慮進去,求得週期後,先從任意為起點,往後的 1 週期內找 local maximum,此點即為 peak value。下個起點,則由目前的 peak value 位置往後移動 2/3 週期,不直接移動一整個週期是怕有誤差,一直重複上列動作就可以找出所有 peak value;同理,也可以找出所有 valley value,最後結果如下。

上圖的藍色 envelope 是原訊號,紅色 envelope 則是有 peak & valley 為點作 spline function 而成的結果。將藍色減掉紅色,就是下圖的藍色。
從上圖來看,紅色 envelope 還滿貼近原訊號的,本以為扣掉後剩下的訊號會變很少,但事與願違。原因是出在 spline function 造出來後雖然很貼近,但仍有些區域是差得較遠的,紅直線跟青直線分別是原本的 peak & valley 所對照下來的位置,這兩個位置扣掉後都是 0 ,但其他位置卻有相差到 +1 / –1 的大小。
接下來,我將試著將半週期內所有的 peak & valley,套用 monotonic increasing/decreasing 的條件後再看看結果。
0225-Memo:
- 觀察這個失敗的實驗,看看是否做無限迴圈後能擷取出f0。
- 找論文看有沒有人用HHT做修改來分析聲音。
2009/03/03 Progressive Report
我先給大家看一下上次提到的「半週期內所有的 peak & valley,套用 monotonic increasing/decreasing 的條件」的結果。

這個訊號的週期約在148-150個sample左右,f0差不多在297-300。大家可觀察到無論是紅點(peak)還是黑點(valley),從最大值開始算半個週期內皆呈現 monotonic decreasing,下個半週期則呈現 monotonic increasing。粉紅色線為紅點及黑點所建連線的平均線。
不過,藍線減掉紅線的結果如下圖。

很明顯的,300hz 的波形還是有留一些能量,原因是因為粉紅色線的極值沒有緊緊貼在原訊號的極值上,導致減掉後仍留有能量,相較於其他波形的能量甚至還滿大的。
隔天,我試著將原訊號的極值同時加到peak/valley兩邊的陣列資料中,這樣照 spline function 時至少在極值的地方會重疊。結果如下圖。

原訊號的頻譜: 平均線的頻譜:


原訊號 - 平均線

已知問題及解法:
做完第一次後,剩下的訊號其300Hz, 600Hz, 900Hz 的能量明顯掉了許多,因此第二次再做時,不能再以原本的週期來作為 monotonic inc/dec 的判斷,否則造出來的spline function會有爆走問題,如下圖。解法: 先用簡單的pitch detection算出目前能量較大的週期後再做第二次實驗。
第二次 第三次


Bug: 找出在做第一次時16000-21000, 25000-33000 區域的振幅大小有一點小爆走的原因。(而且還只有下方有爆走)

2009/03/06
上面的Bug 解決了,原因出在有些區域的「最小極」沒有被列入spline function points,導致造出來的波形在某些情況下會有點誤差。
雖然問題解了,可是出來的結果還是跟上圖差不多,為了方便解釋一下原因請看下圖。

圖中有兩個紅圈圈,紅點跟黑點有全部找到,可是左紅圈內的結果卻比右紅圈內的結果較好,why? 其實這就是訊號的特性,左紅圈內的黑點較集中,所以 spline function 造出來的envelope較貼近原訊號,但右紅圈內的黑點較分散,所以會有波形振幅不一的情況。
這個「現象」目前我不將它當成「問題」,之前之所以成為「問題」的原因是在16000-18000這段的頻譜,在經過三、四次loop後高頻的能量不減反增,但現今已經沒這問題。這裡補一下圖:
0303版,第四個loop後剩下的波形,及27825點該frame的頻譜:


0306版的:


我將繼續往下做,讓週期是 adaptive 的,再看看結果如何。
2009/03/10
老師在3/7的留言中提出一個疑問: 「經過第一次decomposition後, peaks降低了, 可是noise floor也變大了. 這是甚麼原因呢?」
我紀錄一下大家的看法。
老師:
Spline function 是採用 non-uniform sampling 的作法,跟 Fourier Transform 觀念背道而馳,因而可能造成這種現象。(ps. 這邊不太懂 non-uniform sampling 可能造成哪些結果)
Spline function本身main lobe不夠尖,side lobe也不夠小,換成 sinc function 可能會比較好。
DNA:
有時候別太相信 Cooledit …,它的db scale不知道到底對象是誰。
Showmin:
我翻了下課本,發現兩個訊號點對點相加時,能量本來就有可能會大於在頻率上的點對點相加,只要兩者 FFT 出來的實部係數or虛部係數異號。
|x1| + |x2| >= |x1+x2|
小結: 這種現象會不會影響結果還不知道,先紀錄一下。
最後貼一張圖,我在範圍介於 +-10 之間造一個 sinc(x),而且只取15點。然後,用這15點座標來分別造出新的 sinc 跟 spline,出來的結果如上圖,spline function較平緩。下圖則是上圖做 abs(fft(x)) 的結果。

2009/03/17
1. ACF用來判斷pitch period不適用於我們的實驗,因為我們無法將某一pitch的能量完全扣除乾淨。
2. 接著我讓pitch period隨著loop數減少,前兩圈的結果如下。


即使我將起始點位移的距離改小,還是有一些點沒有找到。

是的,這是bug,解決方法很簡單:在找一個週期內的極值時,順手將這個值加到 set 中。之前是只有在判斷 monotonic increasing/decreasing 時才會加進去。當然,在這種情況下極值可能會被加到不只一次,但不影響程式執行的。最新結果如下:

3. spline function effect
這個問題前面就有提過,就是兩個點距離如果有點遠,但值卻差不多大,則spline function會凸出來。上面的結果雖是正常,但只要換到其他時間點來觀察,依然有問題。

這個圖的點其實都有找對了,但卻因 spline function 的特性造成有凸出來的 effect。
投影片下載:這裡
DNA:
何不試著在原訊號後面較穩定的地方找一段完整週期訊號,以此為 template,然後將原訊號拿來減掉這個template,template的能量可隨著該frame而調整。
2009/03/18
由上面第3點的結果我們可以發現,在訊號的能量都差不多時(noise-like),用新方法是滿容易因spline function爆走的,所以老師提供一個實驗方式,要我第一圈先用新方法,第二圈用EMD,看看做完EMD後能否再讓訊號「有起伏」。這個答案是肯定的,請看圖。
第1圈用新方法求得的平均線。

第二圈改用EMD,下圖為EMD做10次後的結果。

做完EMD後,用原訊號扣除上圖即為下圖。很明顯下圖的波形「有起伏」,那理論上再回頭用新方法來找應該很棒,可是為何平均線會找得沒有第一次好呢?這是因為第三圈的週期只剩 150/3 = 50,點的距離較寬而無法將最大值納入 min set,反之亦然,也無法將最小值納入 min set,所以平均線雖然沒有爆走,但卻沒那麼貼。

如果週期維持在150的話就會好多了,當然一樣會有spline function effect,而且點距離越寬越明顯。

第四圈,再做 EMD。

第五圈,再回頭用新方法。此時可以發現用新方法或用 EMD 效果都差不多了。

目前有些疑問,再找時間跟老師討論。
OpenCL
看來nVidia有意要開放OpenCL變成Open Standard
不過當然是為了賺錢.... Maket Builder 這個字還真有意思
http://www.channelregister.co.uk/2009/03/17/opencl_demo/
不過當然是為了賺錢.... Maket Builder 這個字還真有意思
http://www.channelregister.co.uk/2009/03/17/opencl_demo/
2009年3月17日 星期二
Bus Protocol In TLM2 - 宗胤
我大概訂了系統所要用的Protocol,基本上我只是遵循TLM2中所定義的Base Protocol來實作系統的Protocol,另外我使用AT的Coding Style來實作這個Bus。
而TLM的Base Protocol的在AT中的實作方法有分許多種,如backward path、return path、timing annotation等。我所用的是如下圖所示的timing annotation:

所以由上圖可看到一開始initiator傳了10ns到target,接著target會將收到的payload放到一個payload event queue中,經過10ns才會開始處理這次的傳輸(即Begin_Req開始)。而下面的End_Req也是一樣。
系統架構:

整個系統流程大概如下:
- initiator設定好payload的參數,並且設定phase為Begin_Req和決定delay後利用nb_transport_fw送至bus。
- bus根據payload中的addr將payload送到對應的target
- target收到payload後,等待delay的時間後,設定phase為End_Req和設定delay,再使用nb_transport_bw將回應送至bus
- bus再將回應送到對應的initiator
- initiator收到回應,等待delay時間後,完成此次的Request
- 當target完成payload所指示的指令後,開始Begin_Resp的phase,整個流程基本上與Req相似,只有傳輸的方向相反而已
基本上我會照這個來implment整個系統。
----------------------------------------------------------------------------------
03/17
補上Coware上關於Bus的分析工具:
Bus Contention Statistics & Bus Contention Trace

Connection Bus Utilization & Master Wait Total & Master Wait Trace

Transation Counts & Transation Duration

Connection Bus Wait & Transation Throughputs & Transation Trace

接著關於今天提出了問題:
- 關於Delay Time,由於沒有Spec之類的東西,所以我就自己定Delay time的大小
- 然後關於Bus的Implementation,有些錯誤的地方,如queue payload會將它更正
2009年3月14日 星期六
CUDA - Vivian
[090314]
架構介紹
架構介紹
‧ CUDA中,分為host和device兩部分。Host通常是指CPU。而 Device是host的coprocessor,它有自己的memory,可以跑平行的threads,在這裡我們指GPU,然而它也可以是其他的parallel processing device。在Device上跑的程式區段,我們稱為kernel。
‧ In CUDA program, serial 程序交給host (CPU)來做,而其中可以highly parallel的部分,我們寫成kernel function,放到device (GPU)上執行。
流程簡單敘述如下,host端將資料和kernel給GPU,GPU執行kernel,CPU在這同時可以做其他的事情或是等待GPU的資料return。

Serial code executes on the host while parallel code executes on the device.
‧ Thread Hierarchy
1. Thread : 執行的最小單位,每個thread都有一個獨特的threadIdx , a 3-component vector,so threadIdx can be 1D , 2D, or 3D, 方便我們去 domain 程式使用的vector 或 matrix的元素。
數個Threads組成一個block。
Note : GPU上的thread 較 CPU上的light weight,因為是用硬體去做,耗費的cycle較少。但是CPU到GPU之間存取等會耗掉不少時間,因此只有當程式能"highly" parallel,整體的效率才會有顯著的增進。
2. Block : 同一個block的threads可以使用共用的share memory來合作或同步,此外,__syncthreads()函數也可以使block中所有的threads都同步到了這個點時,才讓所有的threads繼續執行下去。目前的GPU一個block可以包含512 個threads。
數個Blocks再組成grid,同樣地,一個block 有獨一的blockIdx, which can be 1D or 2D.

‧ Memory Hierarchy
1. register & local memory : 每個thread有自己可以存取的 registers,在 kernel function 裡宣告的 automatic variable 會存在 register,但是當 automatic variable 數量多於一個thread可使用的register數量,或是 array型態的變數,以上這些會存在local memory。local memory 實際上是在 DRAM,速度較register慢許多,使用上要謹慎考慮效率問題。
2. Shared memory: 同一個block的threads可以存取的共同memory,效率快,它的Lifetime 與此所屬的block一樣長。
3. Global memory: 相當於GPU的DRAM,可以被host和device的每個thread存取,可以用於host和device交換資料使用,但是data access latency很長。

*All above figure from Nvidia Programming Guide.
*參考資源
Nvidia CUDA document
國網中心CUD教學課程
Hotball's Hive
-------------------------------------------------------------------------------
大家好,我是碩零的新生Vivian,也可以叫我小聽~
下次會介紹關於programming的部分。
2009年3月6日 星期五
SIMD programming -- 雙魚
文件名稱:Cell Broadband Engine Programming Handbook
從第22章「SIMD Programming」開始看
已經看完第一節 SIMD Basics
∮SIMD Basics
1. SIMD: one instruction to be applied to the multiple data elements of a vector in parallel
2. Vectors are also called SIMD operands or packed operands.

→ 一個vector裡有4個element
3. SIMD coding 舉例



→ SIMD作法則是把b、c memory stream都向左shift,利用 vector-add instruction 把數值相加,相加完的數值先向右shift,再存回a中對應的位置。
4. Auto-SIMDization:有些撰寫程式要注意的準則,按照準則能讓程式被Compiler有效地SIMDized
(1) Memory 要 data aligned,data存在記憶體中要盡量對齊。
(2) 盡量用array,不要使用pointer去存取資料。
(3) Function calls are not SIMDizable,因為Compiler可能會不知道function call 裡面的code,最好用 marco 跟 inline。
(4) Trip Count 至少要超過3次,否則Compiler不知道alignment。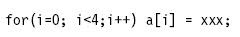
→ trip count=4,如果a[0] is aligned 可以 auto-SIMDized
(5) 有相同的Left hand value比較好,可以用select bits instruction來SIMDize。
從第22章「SIMD Programming」開始看
已經看完第一節 SIMD Basics
∮SIMD Basics
1. SIMD: one instruction to be applied to the multiple data elements of a vector in parallel
2. Vectors are also called SIMD operands or packed operands.

→ 一個vector裡有4個element
3. SIMD coding 舉例


→ 一般作法是先把 b[1]、c[3]先load出來,將兩者相加後store回a[2]

→ SIMD作法則是把b、c memory stream都向左shift,利用 vector-add instruction 把數值相加,相加完的數值先向右shift,再存回a中對應的位置。
4. Auto-SIMDization:有些撰寫程式要注意的準則,按照準則能讓程式被Compiler有效地SIMDized
(1) Memory 要 data aligned,data存在記憶體中要盡量對齊。
(2) 盡量用array,不要使用pointer去存取資料。
(3) Function calls are not SIMDizable,因為Compiler可能會不知道function call 裡面的code,最好用 marco 跟 inline。
(4) Trip Count 至少要超過3次,否則Compiler不知道alignment。

→ trip count=4,如果a[0] is aligned 可以 auto-SIMDized
(5) 有相同的Left hand value比較好,可以用select bits instruction來SIMDize。

{kind=link}
{kind=link}
{kind=link}
{kind=link}
訂閱:
文章 (Atom)